[Paper Notes] Efficient Memory Management for LLM Serving with Paged Attention (vLLM)
Dissecting Paged Attention and vLLM Inference from first principles.

Abstract
Problem: KV cache in LLM serving limits batch size and throughput, if not managed efficiently. The size of KV cache grows and shrinks dynamically in a request. Roughly ~30% of the memory is used for KV cache in a NVIDIA A100 40GB GPU. When not managed efficiently, this may lead to memory fragmentation (unused scattered pieces) and redundant duplication.
Proposal:
PagedAttention - an attention mechanism inspired from virtual memory and paging techniques of operating system.
vLLM - an LLM serving system that enables
near-zero waste in KV cache memory
KV cache sharing within and across multiple requests → further optimises memory usage and increased batch size
Experimental outcome: 2-4X improved latency as compared to FasterTransformer and Orca (at the time of publication)
Introduction
GPT-like LLMs are auto-regressive in nature: generate next token based on previous tokens and input sequence. For each text input, this expensive quadratic generation process continues till the LM spits out <|EOS|>. Its inherent sequential nature removes tensor-parallelism and makes it memory-bound.
To generate (decode) a token at step t, it has to read all the t-1 Keys and Values for each transformer layer (or compute prior to KV cache idea). As t grows, so does memory usage, making it memory bound.
Though to improve throughput further on the base idea, we can batch multiple requests together, so that the idle compute and memory can be put to use for more requests at the same time; inefficient memory management can lead fragmentation and underutilisation of compute and memory, hence further limiting throughput.
As shown in one of the data points, a 13B LLM on 40GB RAM A100 GPU takes upto 65% for storing the static state (weights) of the language model, where as upto 30% are used by the dynamic states (more commonly referred in context of transformers as KV cache). Managing this 30% usage by KV cache becomes tricky as most serving systems store the KV cache of a request in contiguous memory. The catch however is, we don’t know how much to cache and for how long for a request. KV cache grows and shrinks dynamically, and the lifetime and length is not known as priori.
KV cache grows per request only grows as the model keeps generating a new token, hence adding a new Key-Value pair to the cache at each step. Once a request is processed, the stored cache is evicted. Unless we are batching the requests, the system waits till all the requests in the batch is processed, then frees up the contiguous memory allocated for the KV cache.
This contiguous memory allocation and de-allocation poses two problems:
Internal and External memory fragmentation
systems pre-allocate a contiguous space based on request’s/batch’s maximum sequence generation length (max_seq_gen_len or batch_size * max_seq_gen_len).
But not necessarily all the requests are of max_seq_gen_len (i.e., 1024, 2048, etc.). Some request may be way shorter (gen_seq_len (i.e. 10, 20) << max_seq_gen_len. In such cases, even though the request’s input tokens is less, hence the total number of generated tokens is less the max allowed generated tokens, the systems still end up allocating an entire space meant for max number of generated tokens, leaving large chunk of space unused throughout the request’s lifetime. This is internal memory fragmentation.
Now let’s say we want to accommodate a new request or batch of requests. Even though we may have cumulative free space to allocate for the KV cache, but we may not be able to do so cause the available memory ain’t no contiguous. It’s like we have enough space in a Jar to add one more cookie, but we can’t because we have not organised the existing cookies efficiently. This is external memory fragmentation.
No KV sharing across decoding streams or across requests
Decoding techniques like beam search and parallel sampling logically share the same prefix tokens. However, each beam or sample must be represented as a separate batch entry with its own KV slice because:
each beam writes different next-step KV vectors
beam reordering requires physically copying KV rows
KV tensors are stored as fully contiguous layouts without indirection
Thus, prefix KV must be duplicated for each beam or sample, even though the content is identical.
same applies for sharing KV cache across requests. In many LLM-based applications where requests share the same system prompt or instruction prompt, or even prefixes; the memory sharing wasn’t possible because of contiguous allocation, leading to multiple duplicated copies.
So, no efficient reuse of caches and no memory sharing even though there is logical sharing. The paper proposes the following to tackle the above challenges:
Paged Attention
Instead of storing the KV cache in a contiguous memory, store them in blocks. Each block (equivalent to pages in OS) can store fix number of tokens (bytes in OS) per request (process in OS).
This reduces internal fragmentation by using small block sizes (so that only a small chunk of memory may get wasted per request) and manages allocation on demand.
fixed block size → GPU layout converted into identical slots of fixed sizes → eliminates external fragmentation.
Enables memory sharing, cause now requests or decoding branches/streams can refer to the blocks of shared KV caches instead of having to copy the entire cache.
vLLM
distributed LLM inference engine with near-zero waste in KV cache memory.
proposes block-level memory management and preemptive request scheduling (allowing interrupts on an ongoing request instead of waiting the request/batch to finish → enables KV reuse & continuous batching).
Background
Primer on Transformers
Jumping straight into the core of any transformer-based LLMs: Self (/Multi-head) Attention Layer. For input hidden state sequence,
self-attention layer houses the following computations on each position:
calculate query, key and value
\(q_i = W_q x_i; k_i = W_k x_i; v_i = W_v x_i\)mat-mul query and key, scale by dimension
\(q_i^T k_j / \sqrt{d}\)take softmax → (causal) attention
\(a_{ij} = \frac{exp(q_i^Tk_j/\sqrt{d})}{\sum_{t=1}^{i} exp(q_i^Tk_t/\sqrt{d})}\)
Note that, in the denominator, we sum the exponentiated attention logits up-until the current step i, for t = 1 till i. Why? To keep it causal, as don’t look at future tokens while calculating the attention score of the present token.
calculate output as weighted average over the value vectors
\(o_{ij} = \sum_{j=1}^i a_{ij}v_j\)
Observation: query q_i is calculated once per iteration, where as all the key and values k_i and v_i need not be calculated every iteration. While calculating attention output at step i, we need key and value vectors from 0 to i-1; similarly for i+1, we need 0 to i. So at each step t, we can cache the Keys and Values up until the t-1 step, and when we calculate the K_t and V_t for that step, we can just add this new pair to the existing cache. → Essentially what KV cache does.
This sequential generation is hence memory-bound and cannot benefit from tensor parallelism per request. Though we still can utilise parallelism elsewhere in a request. Given a prompt, the generation can be decomposed into 2 phases: The Prompt Phase and The Autoregressive Phase. The later one we discussed. The prompt phase is when the LLM generates its first output token. As the whole user prompt is known priori, this phase can efficiently use tensor parallelism.
Batching Techniques
[Not the main focus in this paper]
Batching improves compute utilisation
Yet, batching requests to an LLM service is non-trivial, because:
make earlier requests wait for later ones, or delay incoming ones till earlier ones finish
different input and output length for requests → if we pad all requests in a batch to same length, we risk wasting compute and memory.
Solution: fine-grained batching mechanisms like cellular batching or iteration level batching.
operate at iteration level instead of operating at request level
After each iteration, completed requests are removed from the batch and new requests are added.
This way, a new request can be processed after waiting for a single iteration, not completion of a single request or entire batch to complete.
Memory Challenges
Pretty much what we have discussed so far.
Larger KV cache
KV cache for a single token in a 13B OPT model: 2 (key value pair) * 5120 (hidden state dimension) * 40 (number of layers) * 2 (bytes per FP16) = 800KB; max KV cache for 2048 tokens: 800KB * 2048 = 1.6GB per request.
Even if we utilise the entire memory to store KV cache only, a single GPU can still only accommodate 10s of requests. Memory is a bottleneck here.
Decoding algorithms
when multiple samples are requested of a single input prompt, KC cache of the prompt part can be share to optimise memory usage → upto 12% of total KV cache memory as per experiments reported.
Autoregressive generation phase restricts cache sharing as each generation is dependent on the context and the position.
The extent of sharing depends on Decoding algorithms in play. Beam search enables larger sharing (upto 55% memory saving as reported).
Request scheduling for variable lengths
KV cache grows as more tokens are generated. What if at one point, the system runs out of memory before completing a request? → preemptive scheduling to pause, swap, etc.
Memory management
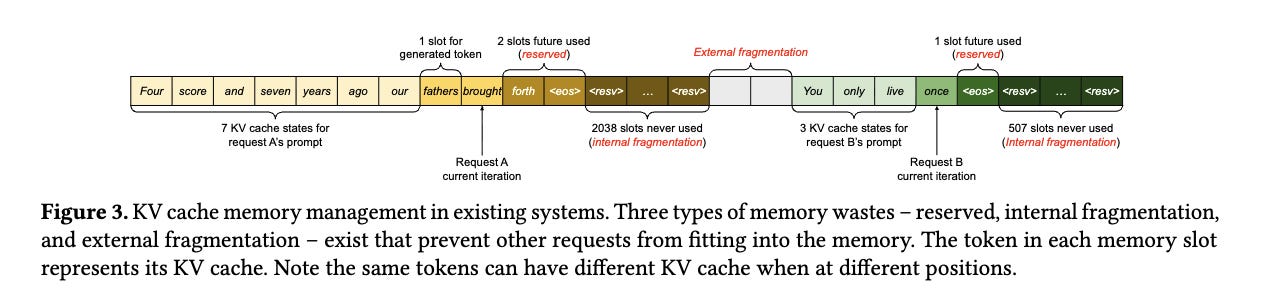
pre-allocation leads to the following memory wastages:
reserved slots
reserved for future token generations so that new tokens can be stored in the same contiguous memory chunk.
Although reserved slots may be used in future, at least some if not all; reserving space for the lifetime of a request may otherwise be used by other completing/ongoing requests.
internal fragmentation
these are the reserved slots who remained unused even after request is complete, cause it generated less than the max allowed number of tokens.
external fragmentation
these are the gaps/holes we leave in memory while allocating the contiguous chunks. Though at some point the cumulative available memory might be enough, the system won’t be able to accommodate a new request cause not enough contiguous memory chunk is available.
Method
Key contributions:
New attention algorithm: Paged Attention
LLM Serving Engine: vLLM
Scheduler to distribute workload and move data between GPU workers
KV cache manager: maps physical KV cache memory among GPU workers
Paged Attention
In previous section, we saw that why we cache the Key-Value vectors to avoid recompute. Paged Attention takes a step further, and breaks the contiguous KV memory into blocks (equivalent to pages in OS). So, when to calculate the Attention Score, we calculate for a block instead of the entire KV cache at once. Each block contains Key-Value vectors for fixed # of tokens. Hence, the previous equation for calculating attention score becomes:
Similarly for the output:
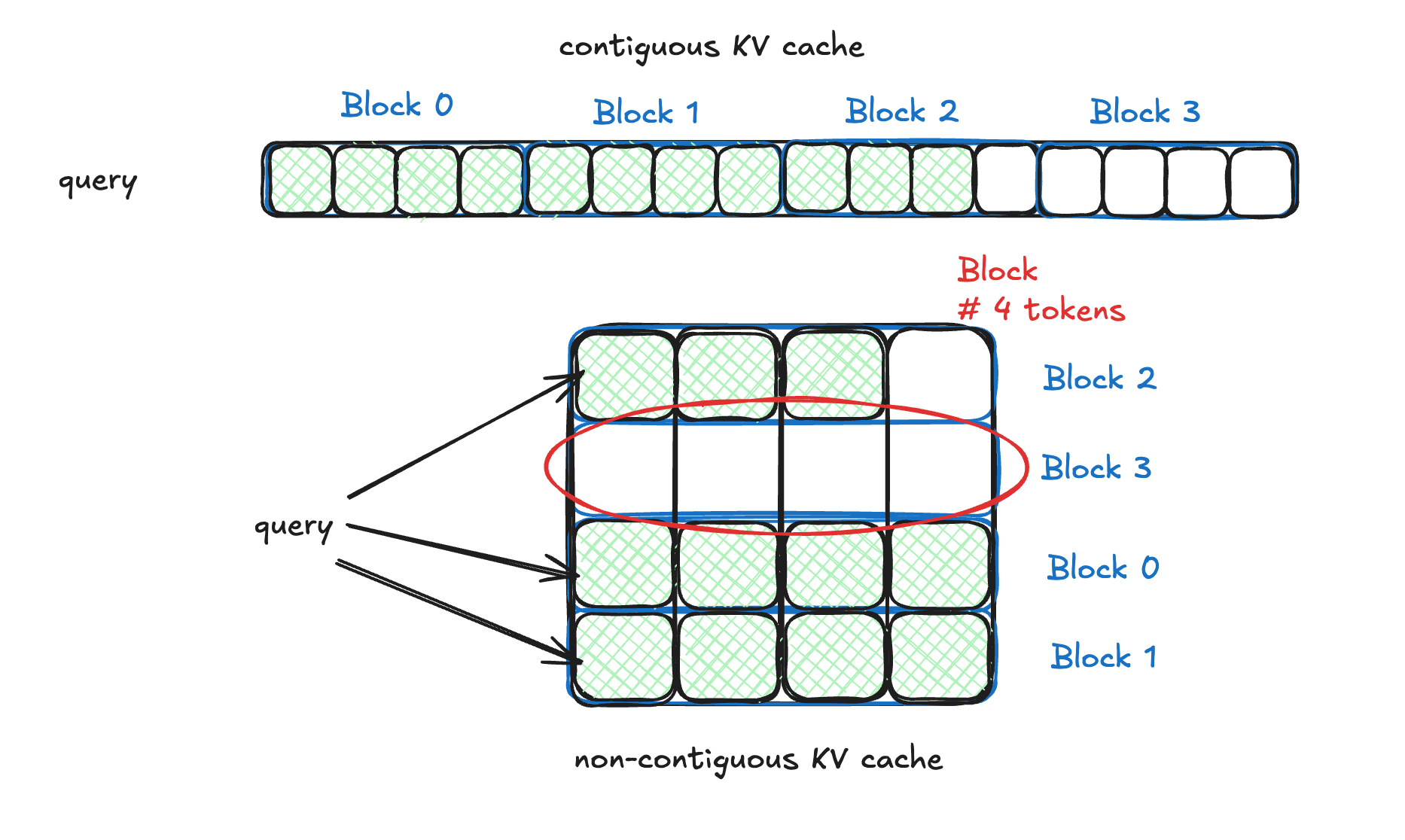
So, we divide the Contiguous KV cache into blocks of size B; total number of blocks: ceil(i / B). Attention Score and output is calculated for each block and then summed over. The logically contiguous KV memory is now stored on non-contiguous physical blocks. A KV cache manager facilitates the PagedAttention Kernel in computation and accessing token’s KV vectors from memory.
Benefits: A fixed Block size limits the memory fragmentation to the choice of block size. Because it allocates/deallocates blocks on demand, at worst, only few slots <= block size may remain empty/unused.
KV Cache Manager
Mainly 3 components: 1) Logical Blocks layout, 2) Block Table mapping logical blocks to physical blocks, 3) physical blocks layout on GPU DRAM.
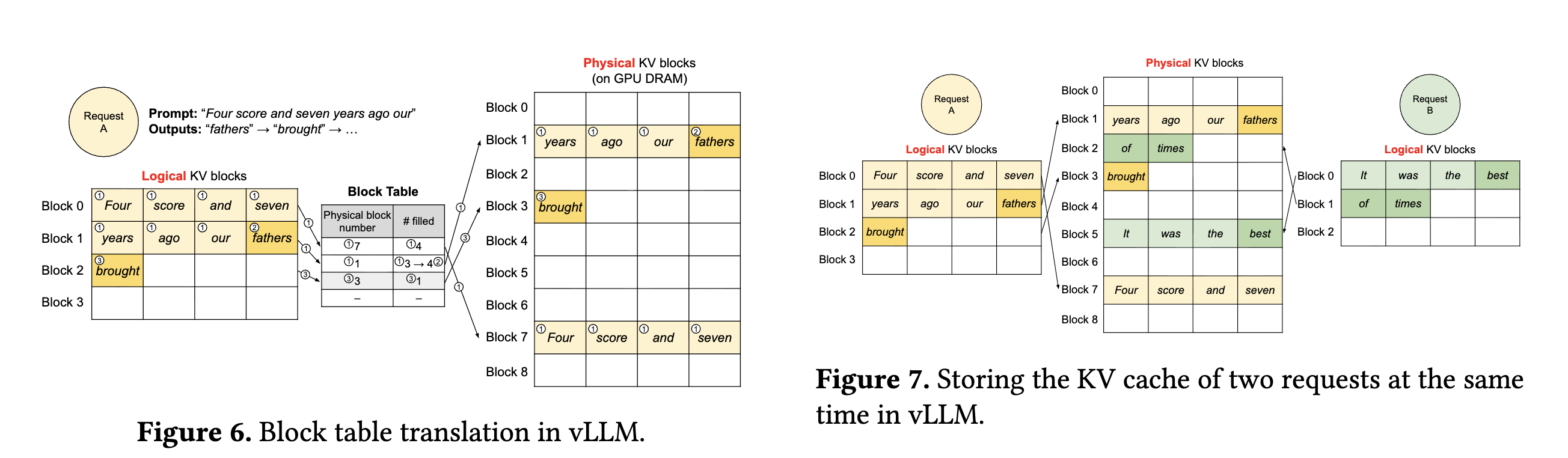
a request’s KV cache is represented in a series of logical blocks filled from left to right as new tokens and their KV vectors are generated.
a block engine on GPU workers allocates a large chunk of GPU DRAM and divides it into physical blocks.
KV block manager maintains a block table where each entry corresponds to a map between the logical KV blocks and physical KV blocks and how many slots are filled.
This set up allows KV cache to grow dynamically as when a new token and its KV vectors are generated, it writes them to the last logical block for that request and the block engine takes care of filling in the physical blocks mapped to those logical blocks.
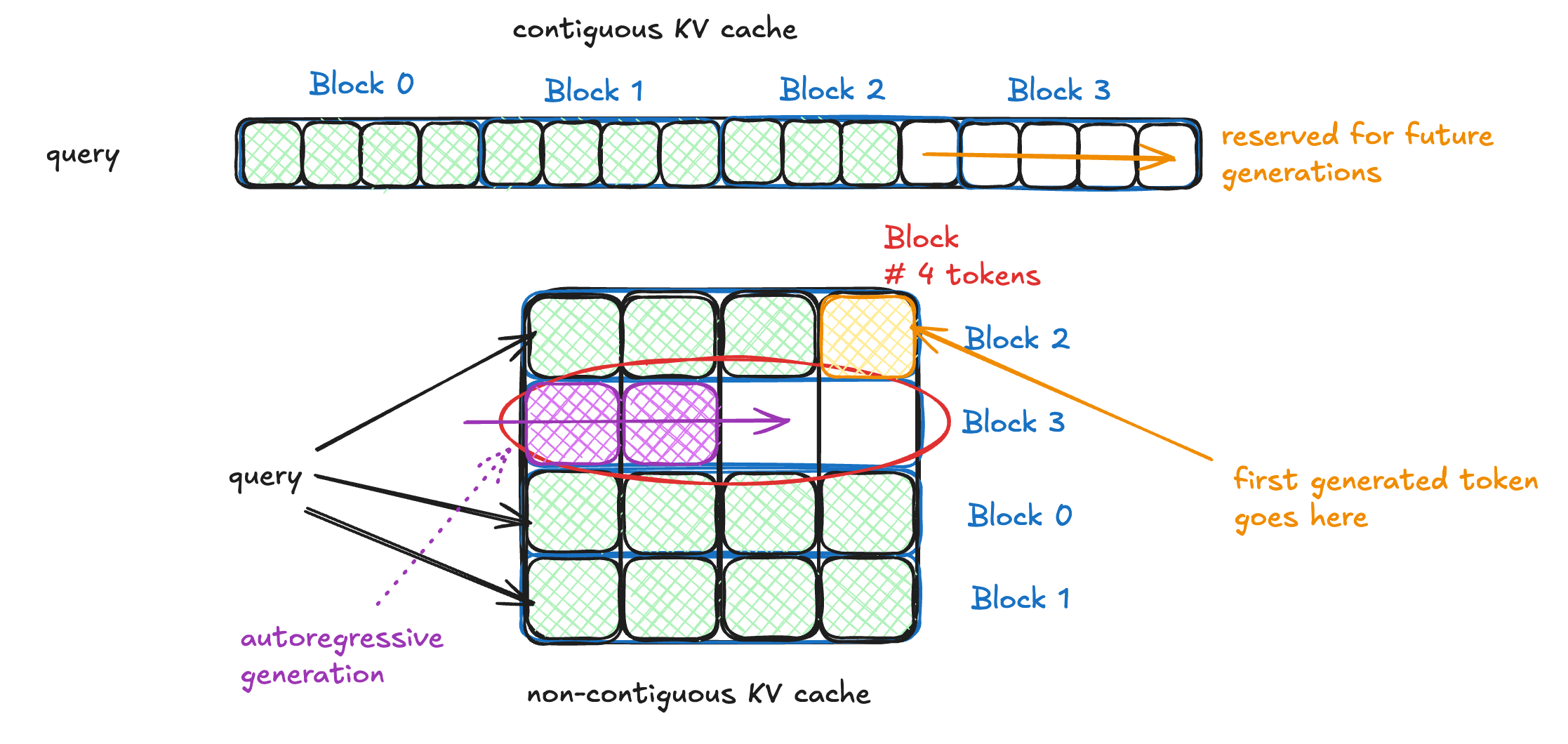
Decoding with PagedAttention and vLLM
Benefitting from the previously discussed block management, vLLM doesn’t need to reserve for max possible generated sequence length initially. Instead, it reserves only for the prompt phase, and allocates new KV blocks on demand.
As shown in the figure above, in the pre-fill phase (prompt + first token KV), it stores the KV vectors in series of logical blocks. As new tokens are generated in the Autoregressive phase, it allocates the generated token’s KV vectors to either last logical block’s unfilled slots or new logical blocks on demand that map to a pool of free physical blocks. As a request finishes token generation, the allocated blocks can be freed (if not shared with other requests, will discuss next).
Improved Batching
Other than reduced memory fragmentation, batching of requests shifts paradigm and improves throughput dramatically. We move from handling batching at request level to handling batching at decoding level i.e. each decoding step is an iteration.
→ Batching at request level:
batch n requests, pad to ensure same length.
even if a request is finished, we wait for other requests in the batch to finish before processing next batch of requests.
no sharing of prefix tokens between requests.
→ Iterating at decoding level:
Because the key-value vectors are stored in non-contiguous memory and accessed via block engine and KV manager from their identifiers, the attention computation kernel can process multiple requests in parallel as a single sequence. Then at each decoding step, it checks if a request is finished (<eos> or max generation length reached). Then we evict unshared KV blocks for that request, and enqueue a new request without having to wait for other requests of the same batch to be processed.
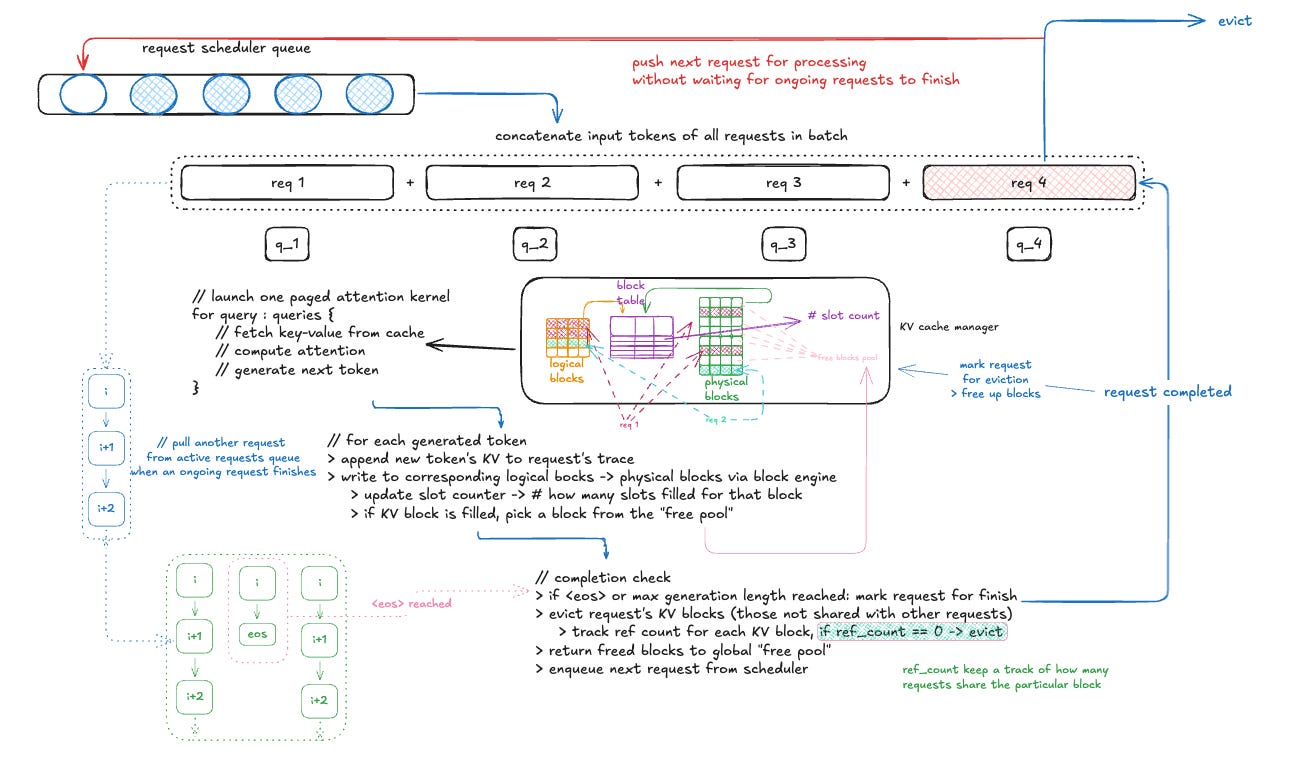
The above diagram shows how vLLM is efficient in basic decoding techniques such as greedy sampling (generate one token at a time per sequence) and increases throughput by order of magnitude. The paper also includes how the system generalises for complex decoding techniques such as Beam Search, Parallel Sampling etc, and enables more efficient memory sharing.
Extension for more complex Decoding Scenarios
→ Parallel Sampling
In parallel sampling, multiple sequences are generated from the same input prompt.
Because the prompt tokens are going to be stay the same for all output generations, the logical blocks of the prompt phase are shared across output generation (decoding) streams. Except the final logical block.
Why leave the final logical block? Cause slots in the final logical block might be reserved for first token generation. Now, to handle that, vLLM implements copy-on-write mechanism with a reference count.
The sharing of KV blocks happens at physical blocks layout. The logical blocks of the prompt phase at each decoding stream point to the same physical block on the block table.
Reference count indicates how many decoding streams can write to the block. When reference count > 2, and a decoding stream tries to write the the last block, it applies copy-on-write to create another block and reduces the ref count of previous block. Now the newly generated block is mapped for the corresponding decoding stream.
This greatly reduces memory footprint for long input prompts.
→ Beam Search
In Beam Search, it retains K top candidates at each decode step, sampling from K * | V | where K is beam width and | V | is the vocabulary size.
As at each step, we are retaining k top-tokens, we can share the prefix tokens among beam candidates if they are the same. Candidates may diverge with new token generations, vLLM frees up outdated candidate’s tokens blocks.
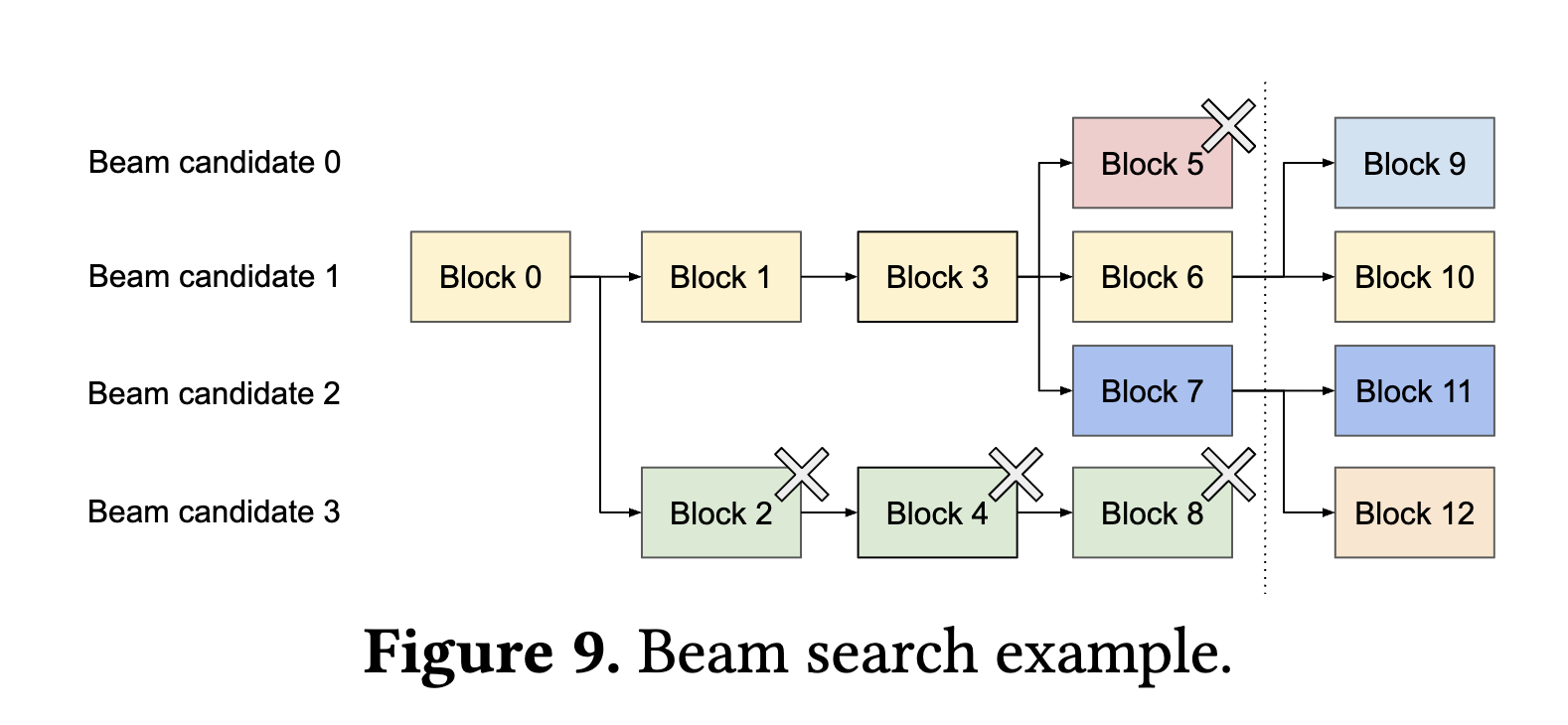
→ Shared Prefix
For prompt-engineering (Agentic might be a better choice of word now) applications, each request often share the same system instruction/prompt.
In such cases set of physical blocks can be reserved for a set of prefix tokens. We can follow the same strategy as parallel sampling to have copy-on-write mechanism for the last block.
System prompt from User’s input can be mapped to the cached physical blocks, and in the prompt phase, only compute the user’s input other than the system instructions/prompts.
This core idea of sharing physical blocks across decoding streams proves to be rather efficient in throughput and optimising memory footprint.
Scheduling and Preemption
FCFS (First-come-first-serve) scheduling policy.
A challenge remains though: what if vLLM runs out of memory (and by memory, I meant Physical blocks) while generating KV for ongoing requests? In such cases, we ask two questions:
Which blocks to evict?
How to recover the evicted blocks if needed?
→ Eviction policies
All-or-nothing: fits well as all blocks of a sequence are accessed together. So, either we evict all blocks of a request or none.
For shared blocks such as in Beam Search (top K candidates), the sequences are grouped together per request. So, again, either we preempt or reschedule all the candidates in a group together.
→ Recover evicted blocks: two approaches
Swapping
copy evicted blocks to CPU (there is a CPU block allocator for that along with the GPU worker’s block engine)
When vLLM exhausts free physical blocks to process new requests, select set of sequences to evict and swap the blocks to CPU and stop accepting new requests.
Once ongoing requests complete, bring back blocks from CPU back to GPU memory and process the preempted sequences.
CPU blocks are bounded by GPU blocks as the number of blocks swapped into CPU never exceeds # of physical blocks of GPU.
Recomputation
Just recompute the KV cache when preempted sequences are rescheduled.
Distributed Execution
vLLM supports Megatron-style tensor parallelism, where the model’s parameters (e.g., attention heads, MLP dimensions) are sharded across multiple GPUs.
Each SPMD process (rank) holds a model shard and a corresponding shard of the KV cache, stored in a paged layout managed by a local KV cache manager and block table.
During inference, all ranks receive the same token IDs for each sequence, compute their local query/key/value slices, and run a PagedAttention kernel using their per-rank block tables to gather the appropriate KV fragments.
Each rank produces a partial hidden-state output, which is then combined across GPUs via all-reduce. KV cache itself is not shared in a single central manager; instead, it is sharded and managed independently on each GPU, with logical positions synchronized by the common decoding scheduler.
Implementation Details
Omitting the details, kindly refer to section 5 on the original paper. tldr; a compact 8.5K Python and 2K lines of CPP/CUDA code with FastAPI server and NCCL for tensor communications across GPU workers.
Kernel Optimisation
Fused reshape and Block write
KV cache are split into blocks, reshaped into a memory layout optimised for block read then saved at positions as specified in block tables.
Fused into single kernel to avoid launch overhead.
Fused Block read and attention
Attention Kernel adapted from FasterTransformer to reach KV cache according to block table and perform attention ops on fly.
GPU warp to ensure coalesced memory access for each block.
Variable sequence length support within a request batch.
Fused Block copy
Single kernel to batch the copy operation from copy-on-write to avoid operating on discontinuous blocks and data movement overhead from cudaMemcpyAsync.
Scaling support for various Decoding Algorithms
Scale vLLM to support various decoding algorithms via three key methods:
Fork
Create a new sequence from existing one (parallel sampling)
Append
Append new tokens to the sequence
Free
Delete the sequence
A combination of the above methods suffice in supporting previously discussed decoding algorithms like parallel sampling, beam search etc.
Evaluation
I will quickly go through the evaluation set up and metrics mentioned in the paper.
Models: OPT {13B, 66B, 175B}, LLaMA {13B}
Server: A2 instances of NVIDIA A100 on GCP
Baselines: Faster Transformer and Orca.
FasterTransformer lacks a scheduler, so the authors took liberty to implement a custom scheduler with dynamic batching similar to Triton. Orca used a buddy allocation algorithm, and makes certain assumptions on output generation length priori and memory reservation for KV cache.
Metrics: Normalised Latency → latency normalised by sequence length. Low latency for high request rate in a high throughput system.
Systems evaluated over 1-hour traces, except the 175B models (cost-bound :)).
Basic Sampling : one sample for request
as request rates increases, latency increases at a gradual pace, but then suddenly explodes → request rate surpassing server’s capacity → increased active request queue.
sustaining 2X-8X request rates as compared to Orca, 22X as compared to FasterTransformer. Except for the 175B model, where the difference is less-pronounced.
Parallel Sampling and Beam Search
Beam search demonstrates greater performance as it allows more KV sharing.
1.3X higher request rates in basic sampling to 2.3X with beam search.
6-10% memory saving in parallel sampling to 37.6%-55.2% in beam search on Alpaca, even higher in ShareGPT for longer sequences.
Shared Prefix
used WMT English to German translation with 1-shot and 5-shot; synthesise requests by adding instructions for translation with examples.
1.67X higher request rates than Orca with one-shot, upto 3.78X with more examples (shots).
Chatbot
Concatenate User conversation history, clip at latest 1024 tokens and restrict output generation length at 1024 → 2X higher requests than Orca.
Ablation Studies
→ Kernel Microbenchmark
20-26% higher attention kernel latency for the block read/writes overhead. Although overall outperforms FasterTransformer in end-to-end performance, but lags behind in kernel level.
→ Impact of Block size
Too small → GPU parallelism not fully utilised.
Too large → risk exposing gaps in memory → increased fragmentation.
Block sizes 16 - 128 lead to optimal performance as benchmarked on Alpaca and ShareGPT. Default block size is set to 16.
→ Recomputation and Swapping w.r..t to block size
recomputation is constant w.r.t to block size, as anyways we are recomputing the KV vectors
Swapping adds more overhead if block size is small → more and smaller data movements between CPU and GPU, bottlenecking PCIe bandwidth.
Larger Block size (>=128)→ Swapping; smaller block size → Recomputation.
Winding Down …
Phew! This was quite a read. I took up reading this paper to understand design nuances of an inference engine, as I am building one at work. Although the scope diverges quite an extent, I look forward to take some time out and implement a smol-vLLM on my cute lil’ 5 years old 1080 Ti, if that’s breathing still.
If you have made it so far, thank you!! Really appreciate the patience put into reading this long notes. Feel free to engage in any manner: via comments or highlighting errors as I tend to make some. Enjoy the read, I look forward to writing more. See ya!
References
vLLM paper: https://arxiv.org/pdf/2309.06180
Paged Attention Blog on vLLM Docs: https://docs.vllm.ai/en/latest/design/paged_attention/
Aleksa’s blog on vLLM: https://www.aleksagordic.com/blog/vllm
Great Writeup!